
防患未然:企业高管如何预测、预防系统宕机,最大化系统可用性
 1433
1433 2024-12-11
2024-12-11
在生产环境中维持数字服务正常运行,必定伴随着通宵达旦的高压工作,我对此深有体会。这项工作责任重大,既要保证快速交付,又要维持系统正常运行并防止宕机。借助 Dynatrace,企业高管现在可以在问题影响客户之前完成预测,防患于未然,减少被动应对。即便发生宕机,Dynatrace 的 AI 驱动自动根因分析也能加速问题修复。最终目标就是提升企业软件的可用性。
● 通过独特的三重 AI 技术组合,预测并预防潜在的系统宕机
● 结合因果分析、预测分析和生成式AI进行自动根因分析,加快问题修复
● 利用端到端跟踪洞察客户影响,帮助确定事件处理优先级
● 通过自动化实现规模化主动防护,在客户受影响前完成系统自愈
要实现根因分析自动化,需要采取全面的方法:通过深入洞察实现端到端和全栈观测,利用实时更新的拓扑结构统一数据,并应用能够即时学习的因果 AI 来应对云原生环境的动态特性。多种 AI 技术的结合让 Dynatrace 更加强大,能够在同一平台上实现预测、预防和自动修复。不过业务才是重中之重,所以单纯监控服务器并没有意义。企业高管真正的业务需求在于理解客户影响,所以必须具备端到端的可观测性。这就是 Dynatrace 为客户解决问题的独特之处。
对企业高管而言,IT 系统宕机是一个重大难题。对于无法从源头预防的问题,最好的选择是在客户察觉之前就解决问题。而要提高处理速度,自动化是必经之路。
“Dynatrace”这个名称已经表明:动态追踪是我们的动作核心。Dynatrace 能够深入追踪从终端用户交互到服务器端全栈活动的完整过程,以此理解依赖关系,进而量化影响、评估状况并确定行动优先级。三重 AI 模式为自动根因分析提供动力,能够在数百万个服务相互依赖和代码行中快速定位问题根源,具有远超人工分析的能力。
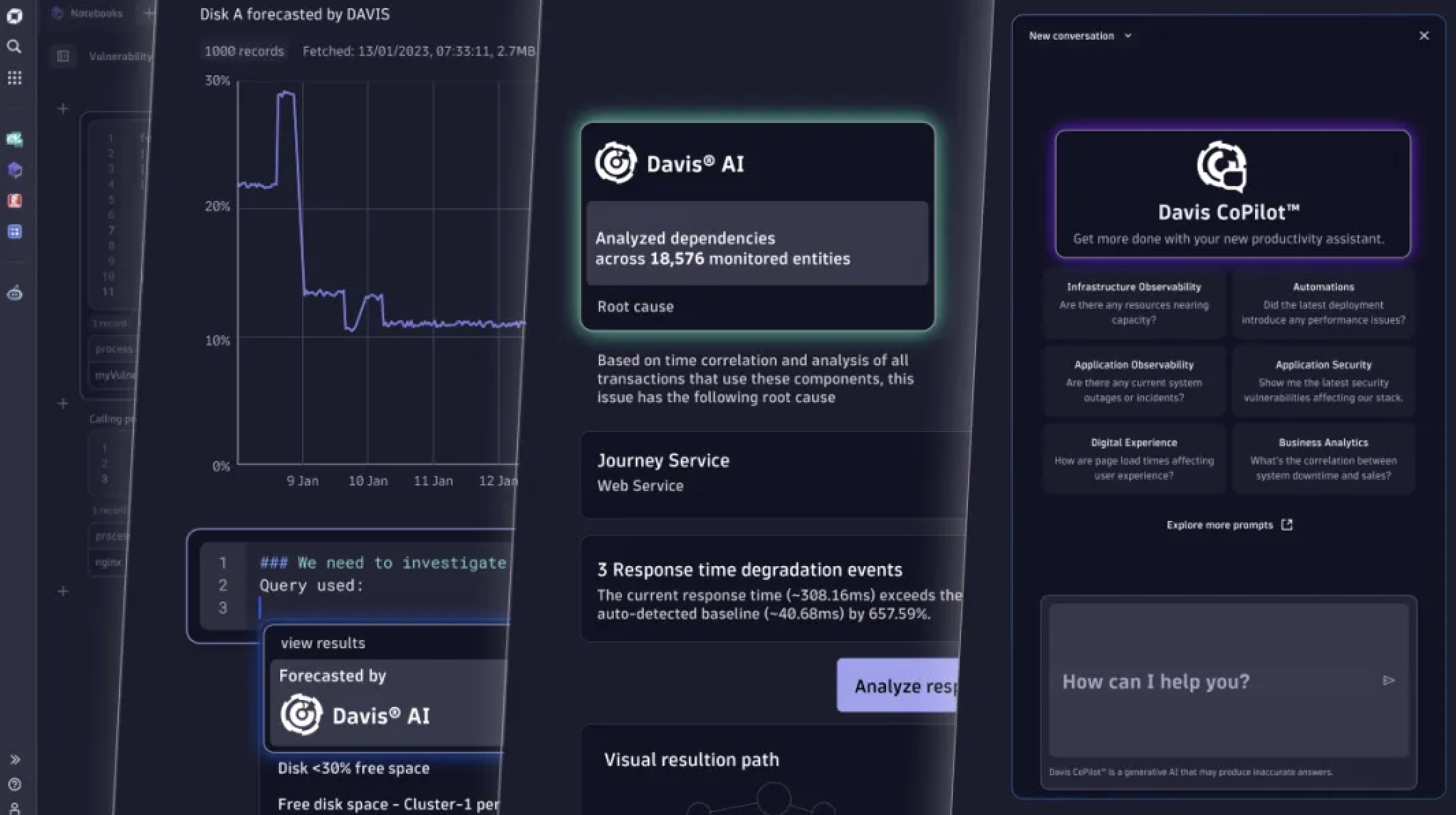
云技术的复杂性和数十亿的依赖关系已经超出了人工管理范围,需要AI来进行分析和理解。Dynatrace 的 AI 能够大幅提升效率,避免告警风暴,可以避免相互推诿,也不用召开紧急会议,从而能提高开发团队的生产力和满意度,消除因告警风暴带来的业务风险。会话回放功能提供直观的证据和事件背景,帮助团队更容易理解和处理根本原因。通过 Dynatrace 的自动根因分析,企业可以将平均修复时间(MTTR)降低90%以上。
Dynatrace 因其三重 AI 能力而广受认可,可以预测和预防问题,自动识别根本原因,从而最大化系统可用性。
随着云原生技术普及与责任左移(shift left),开发团队对生产部署有了更多的控制权。如今软件开发者也要为软件负责,与“抛过墙”的传统方式形成鲜明对比,但这在大型组织中也带来了一致性与合规性挑战。所以我们没有选择“左移”,而是将Dynatrace“向左扩展”,来满足双重需求:开发人员可以轻松安全地访问预生产和生产环境的部署,同时主要的 SRE 和 DevOps 团队也能获得所需的可扩展和自动化的可观测性,保持合规、一致性和系统韧性。最终,标准化的可观测性加上部门用户自助服务,有效减少了工具泛滥和复杂性问题。
那些需要团队24小时盯着仪表板、手动解释数据并按照操作手册执行操作的日子已经一去不复返了。通过统一可观测性数据并应用先进的 AI 技术,Dynatrace 推进了新一代 AIOps 的发展,能够预测和预防问题,并利用自动化实现系统自愈。
根据2024年 AI 现状报告(The 2024 State of AI Report),89%的技术主管期望AI能够改善事件响应,88%期望它能够帮助团队预测并主动解决影响服务的问题,如应用程序故障和安全漏洞。在这个过程中,许多组织尝试用 AIOps 工具改善模式分析,降低噪音,但大多数解决方案只提供相关性分析,不能揭示真正的因果关系。更糟糕的是,系统并不能从过去的宕机中学习,因为训练系统需要数千次生产环境宕机,这是任何企业高管都无法承受的。
要真正预测、预防问题,需要即时捕捉系统复杂性,并在完整背景下持续评估,通过实时映射因果关系的AI来实现。Dynatrace 通过其三重 AI 方法解决了这一需求,在单一框架中结合了因果分析、预测分析和生成式 AI 能力。这种方法无需从过去的宕机中学习,能够实现高度自动化的软件交付流程,最大化系统韧性。
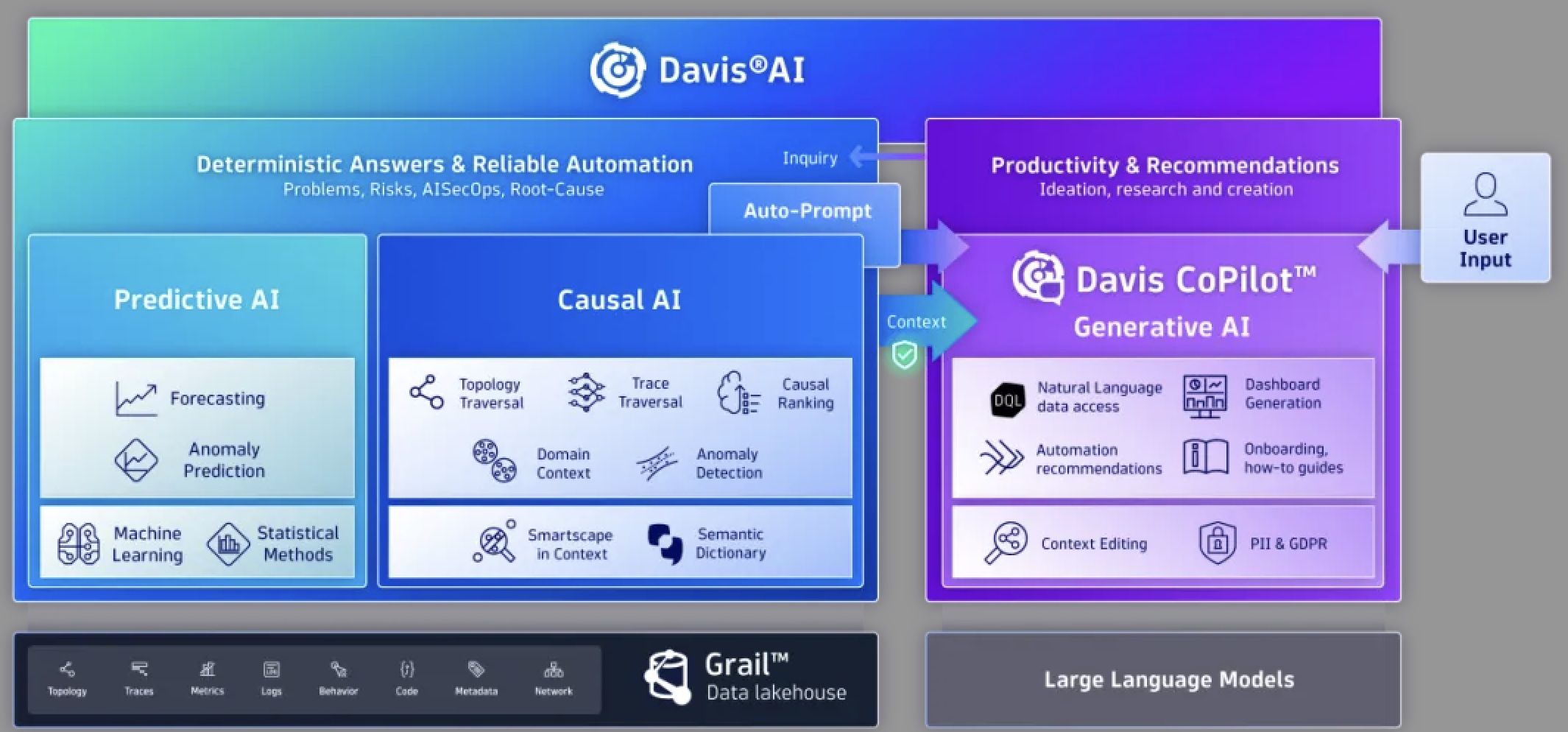
IT 团队还可以在工作流中嵌入质量门,以持续满足通过服务水平目标(SLOs)定义的用户体验阈值,进而可以基于季节性模式预测容量需求,并利用因果依赖关系自动捕捉和预防问题。
要满足不断提高的客户期望,提升系统可用性,需要高度自动化以实现规模化、灵活性和韧性。包括自动扩容、过载保护、自动修复、自动回滚、自动质量门等。最终目标是通过自主云运维实现系统自愈。
因此,平台工程学科应运而生,它从整体角度处理软件、基础设施和交付,始终追求自动化。但自动化不能仅限于技术层面,还需要在业务背景下执行,所以得深入了解影响业务的关键指标,包括用户体验、公共 API 调用成功率、季节性变化规律,以及成本与性能等战略目标。
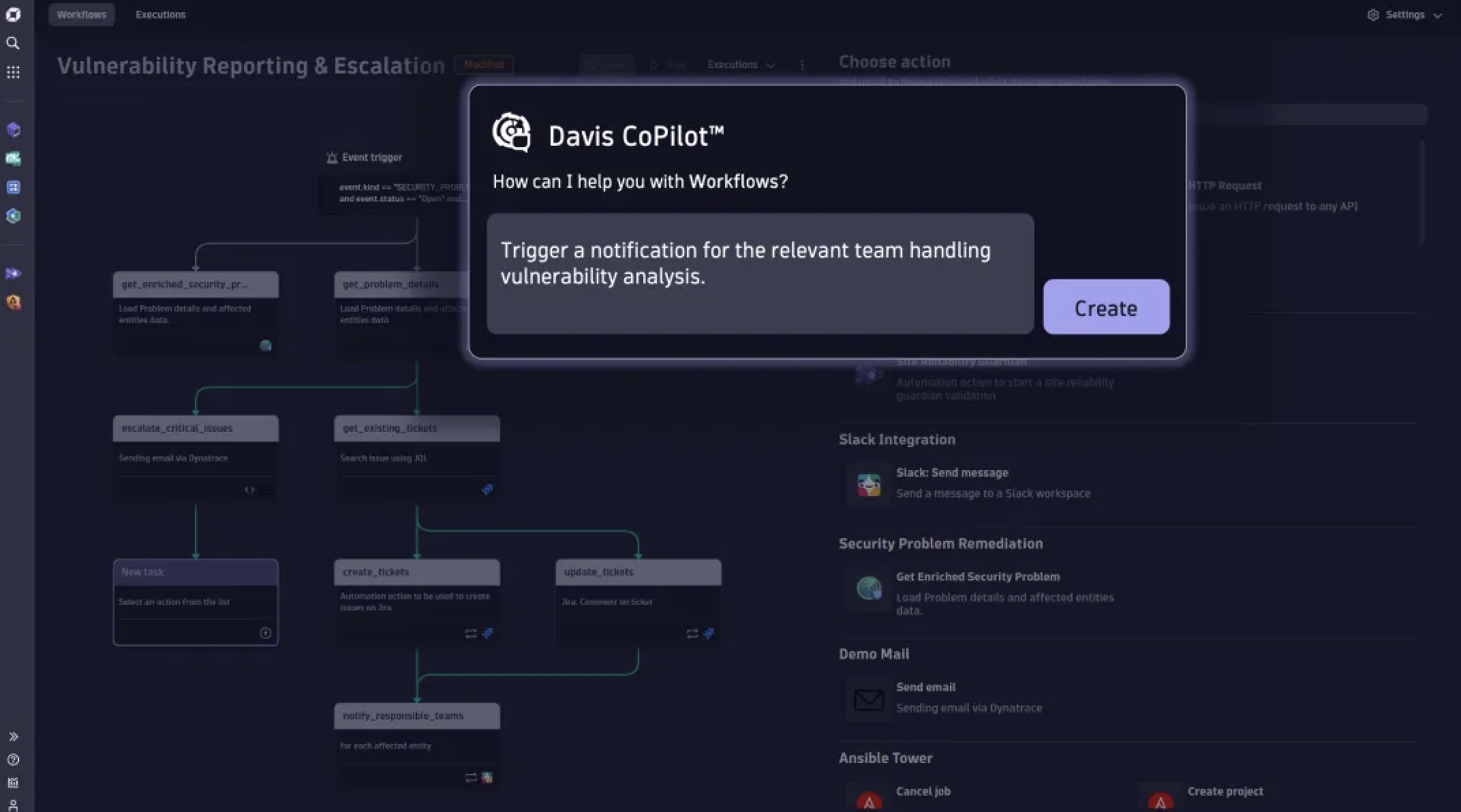
这就是 Dynatrace 的可观测性远远超出传统“观测系统”的地方。Dynatrace 提供的可观测性包含了 AI、分析和自动化功能,可以与平台工程、持续交付和自动化运维集成。这大大减轻了 DevOps、SRE 和运维团队的手动工作负担,使他们能够转向自动化任务。需要注意的是,工作量并没有减少,主要收益在于提高了可用性和安全性,加快了软件交付速度,提升了生产力,并优化了云成本。
欧洲的数字运营韧性法案(DORA)等新的认证和安全法规,正在提高对数字系统可用性的要求。DORA 要求持续合规并能够报告状态,给组织带来了沉重负担。而 Dynatrace 可以通过新的合规助手应用提供额外支持和自动化方案。
同样道理,由于可用性不仅受技术问题影响,还受安全威胁影响,可观测性和云安全必须相互融合,最小化可用性问题。正是在统一的可观测性和安全数据基础上,Dynatrace 的 AI 和分析能力将问题预防和快速修复提升到了新的水平。

 首頁
首頁 
 上一篇
上一篇

 下一篇
下一篇